Here is my book review of the second edition of the book Programmation GWT 2 (author : Sami Jaber). In French since the book is written in French.

Cette deuxième édition fait 21 chapitres (516 pages) alors que la première édition comptait 17 chapitres (461 pages). Soit environ 50 pages supplémentaires.
Elle prend en compte les nouveautés introduites depuis la version 2.0 jusqu’à la version 2.5.
Les développeurs francophones peuvent certainement remercier l’auteur d’avoir mis à leur disposition un livre en français qui est aussi complet et à jour sur GWT.
Chapitre 1
Le premier chapitre présente clairement la structure d’un projet GWT mais aussi les différents modes : mode développement et mode production. Avec une petite introduction à une nouveauté de la version 2.5 : le super DevMode.
Chapitres 2 et 3
Dans le chapitre 2, j’ai apprécié l’honnêteté de l’auteur qui souligne dès le début “la simplicité et la sobriété” des widgets disponibles en standard dans le framework. Les principaux widgets sont passés en revue, avec exemples d’utilisation à l’appui (code Java et CSS, ainsi que des captures d’écran).
Chapitre 4
Je pense que ce chapitre dresse un bon tour d’horizon des bibliothèques tierces (Sencha Ext-GWT, SmartGWT, GWT-DnD, GChart, GWT HighCharts) et des frameworks complémentaires (Vaadin entre autres).
Chapitre 5
L’utilisation de JavaScript dans du code Java est étudiée de façon minutieuse dans ce chapitre : insertion de code JavaScript dans une méthode Java, intégration d’un fichier JavaScript externe, correspondance des types entre Java et JavaScript, etc. L’auteur fournit également des explications sur les types Overlay, plutôt méconnus.
Chapitre 6
La création de composants personnalisés est souvent nécessaire dans un projet et ce livre ne manque pas d’y consacrer un chapitre entier. On y voit de façon détaillée la mécanique événementielle de GWT et le modèle de widget.
Chapitre 7
Ce chapitre décrit les services RPC et dévoile les bonnes pratiques à mettre en place lors de leurs utilisations.
Chapitre 8
Ce chapitre met l’accent sur l’intégration J2EE avec un exemple d’utilisation des EBJ 3 et de JPA. J’ai trouvé l’exemple pertinent et suffisamment illustré par du code.
Chapitres 9, 10 et 11
Ces chapitres expliquent et décrivent amplement le chargement à la demande (code splitting), la liaison différée (deferred binding) et la gestion des ressources (API ClientBundle) à grand renfort de code, de rapports de compilation, de captures d’écran de navigateurs, etc.
Chapitre 12
Ce chapitre rentre dans les entrailles de GWT : différentes facettes du compilateur, fichiers créés, réduction de code (pruning) et optimisations.
Chapitre 13
Le mécanisme de l’internationalisation avec GWT est traité dans ce chapitre. L’auteur aborde et montre bien l’utilisation de l’API i18n, les dictionnaires, les messages, les conversions de types ainsi que l’outillage.
Chapitre 14
Les tests ne sont pas délaissés puisqu’un chapitre entier y est dédié. On y voit l’utilisation de GWTTestCase, HTMLUnit et Selenium. Ce dernier framework est pas mal utilisé dans le chapitre, notamment pour l’écriture des tests fonctionnels (description de Selenium IDE et du module WebDriver). Enfin la notion de mocking n’est pas oubliée puisqu’elle est illustrée avec un exemple utilisant JMock et EasyMock.
Chapitre 15
Ce chapitre sur les design patterns est à mon avis un des plus importants car il liste les bonnes pratiques d’architecture et de conception. Et à mon avis l’auteur a fait un très bon travail en fournissant pas mal de conseils : comment gérer la session, l’historique du navigateur, les traitements longs avec les classes Timer et Scheduler, les patterns Commande, MVC et MVP, etc.
Chapitre 16
J’ai trouvé le chapitre dédié à UIBinder très exhaustif. On y voit la gestion des styles et ressources, l’incorporation des images, la gestion des évènements, le référencement de widgets composites à l’intérieur d’un widget composite…
Chapitre 17
Un très court chapitre qui prend la peine de faire un tour d’horizon du plug-in Eclipse pour GWT. Je pense qu’il montre bien ses possibilités.
Chapitre 18
Un chapitre est consacré aux composants CellWidget. J’ai bien apprécié la description et l’utilisation (nombreux extraits de code) du widget CellTable, très utilisé pour la création de tableaux. La documentation officielle de Google est très bonne sur le sujet mais des explications supplémentaires et de surcroît en français ne sont jamais de trop !
Chapitre 19
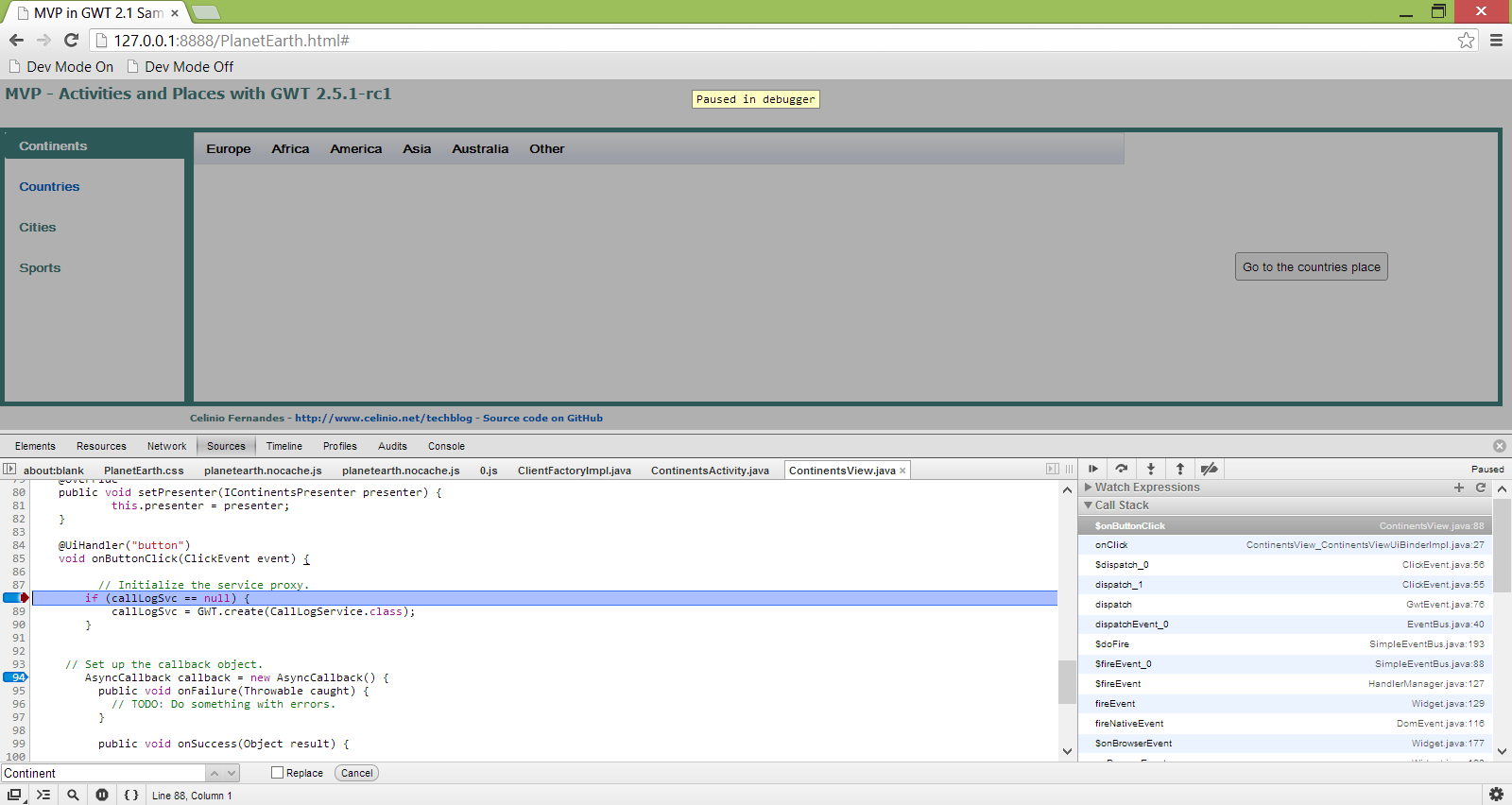
Enfin un chapitre dédié à l’API Activities and Places. À l’heure actuelle il existe encore peu d’ouvrages qui abordent en détail cette API et c’est un gros manque. Dans ce chapitre l’auteur explique longuement cette API complexe et l’illustre à l’aide d’un exemple et d’un schéma décrivant toute la chaîne d’exécution de l’API Activities and Places.
Chapitres 20 et 21
Ces deux derniers chapitres concernent les API RequestFactory, AutoBean et Editors. Tous les deux sont bien riches en code, explications, conseils et avertissements !
De manière générale j’ai beaucoup apprécié l’exhaustivité des explications fournies dans la plupart des chapitres. Mais aussi les conseils et avertissements sur certains sujets complexes.
J’ai aussi beaucoup apprécié l’apparition d’un chapitre entièrement dédié à Activities and Places. L’importance de ce framework dans le développement d’une application GWT mérite en effet un chapitre à lui tout seul et l’auteur a bien veillé à en inclure un mais a également produit un bel effort d’explications détaillées de cette API difficile pour la rendre plus compréhensible et plus assimilable.
Je n’ai a posteriori noté qu’un seul manque dans ce livre : une présentation un peu plus détaillée du super dev mode, qu’on avait annoncé comme une nouveauté très intéressante de la version 2.5. Mais cette fonctionnalité est relativement neuve, notamment au moment de l’écriture de cette deuxième édition du livre.
Sommaire
Introduction à GWT
Chapitre 1 : L’environnement de développement
Chapitre 2 : Les contrôles
Chapitre 3 : Le modèle de placement CSS
Chapitre 4 : Les bibliothèques tierces
Chapitre 5 : L’intégration de code JavaScript
Chapitre 6 : La création de composants personnalisés
Chapitre 7 : Les services RPC
Chapitre 8 : L’intégration J2EE
Chapitre 9 : Le chargement à la demande
Chapitre 10 : La liaison différée
Chapitre 11 : La gestion des ressources
Chapitre 12 : Sous le capot de GWT
Chapitre 13 : L’internationalisation
Chapitre 14 : L’environnement de tests
Chapitre 15 : Les design patterns GWT
Chapitre 16 : La création d’interfaces avec UIBinder
Chapitre 17 : Le plug-in Eclipse pour GWT
Chapitre 18 : Les composants CellWidget
Chapitre 19 : Activités et places
Chapitre 20 : L’API Request Factory
Chapitre 21 : L’API Editors