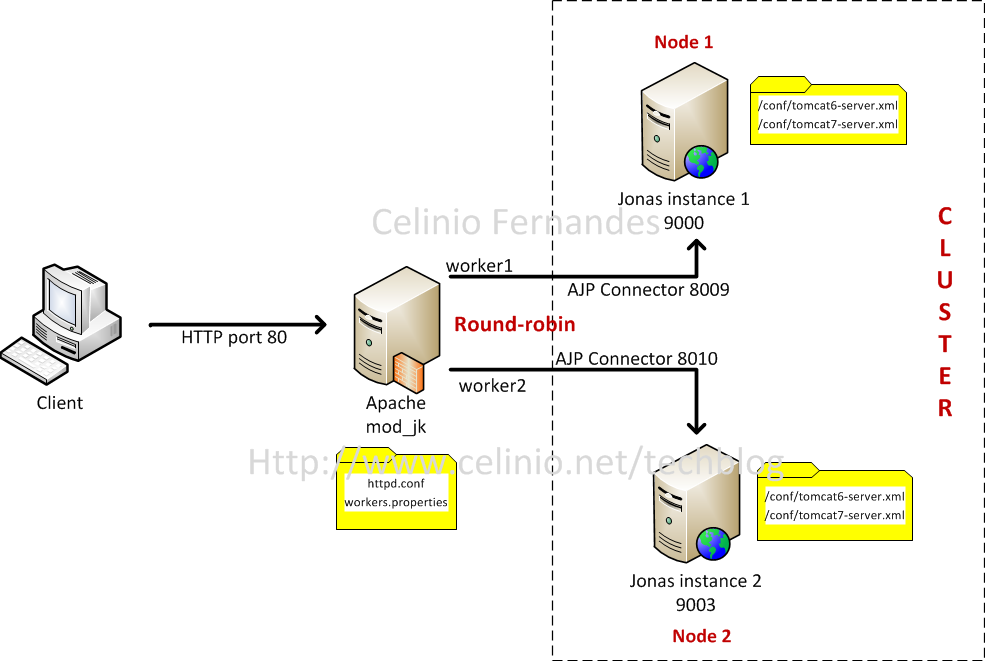
Here are the quick steps to configure a cluster of Jonas instances, with Apache and the module mod_jk.
| Instance | HTTP | AJP Connector | jvmRoute |
| Jonas 1 | 9000 | 8009 | worker1 |
| Jonas 2 | 9003 | 8010 | worker2 |
The Apache web server receives the client requests and forwards them to one of the Jonas instances :